-
[Deep Learning] 딥러닝이란? - 인공지능, 머신러닝과의 구분 및 기초 신경망Artificial Intelligence/Basic 2020. 9. 20. 20:01
인공지능, 머신러닝, 딥러닝?
인공지능, 머신러닝, 딥러닝은 최근 핫하게 떠오르고 있는 키워드들입니다.
그러나 이 단어들이 미디어에서 종종 비슷한 의미를 가지고 있는 듯 쓰여 정확한 상관관계가 헷갈릴 수 있겠다는 생각이 드는데요, 그래서 먼저 세 단어의 상관관계를 정리하고 넘어가도록 하겠습니다.

딥러닝 ⊂ 머신러닝 ⊂ 인공지능 인공지능은 쉽게 말하자면 사람이 할 수 있는 일을 기계가 할 수 있도록 만드는 기술입니다. 예를 들어 알고리즘을 이용해 게임을 플레이하는 프로그램을 만들었다면, 이는 인공지능이라고 할 수 있습니다. 인공지능 중에서도 이렇게 논리, 검색 등을 사용해 우리가 이해할 수 있는 구조로 문제를 해결하는 인공지능을 Symbolic AI라고 합니다.
머신러닝은 수많은 데이터를 통해 그 안의 규칙을 학습해나가는 기술입니다. 사람이 규칙을 명시해주는 Symbolic AI와 별개로 스스로 규칙을 학습해나가는 특징을 가지고 있습니다. 이러한 인공지능을 Non-symbolic AI라고 합니다. 아무래도 사물을 인식하는 것, 말을 이해하는 것 등 사람이 할 수는 있지만 정확한 논리를 설명하기는 어려운 일들을 학습시키는 데에 뛰어난 효율을 보여 각광받고 있습니다.
딥러닝은 머신러닝 중에서도 신경망(Neural Network) 구조를 통해 규칙을 학습하는 기술입니다. 머신러닝 기법 중에서도 놀라운 성과를 내고 있어 아무래도 가장 주목받고 있는 기술입니다. 최근의 뉴스 기사에서 놀랄 만한 성과를 내고 있는 인공지능이 나온다면 아마 십중팔구 딥러닝 기술을 사용하고 있을 겁니다. 신경망을 task에 따라 어떤 구조로 구성해 학습해나가는지가 최근 이 기술에서의 화두인데요, 우선 신경망이 어떻게 구성되어 있는지부터 알아보겠습니다.
Perceptron
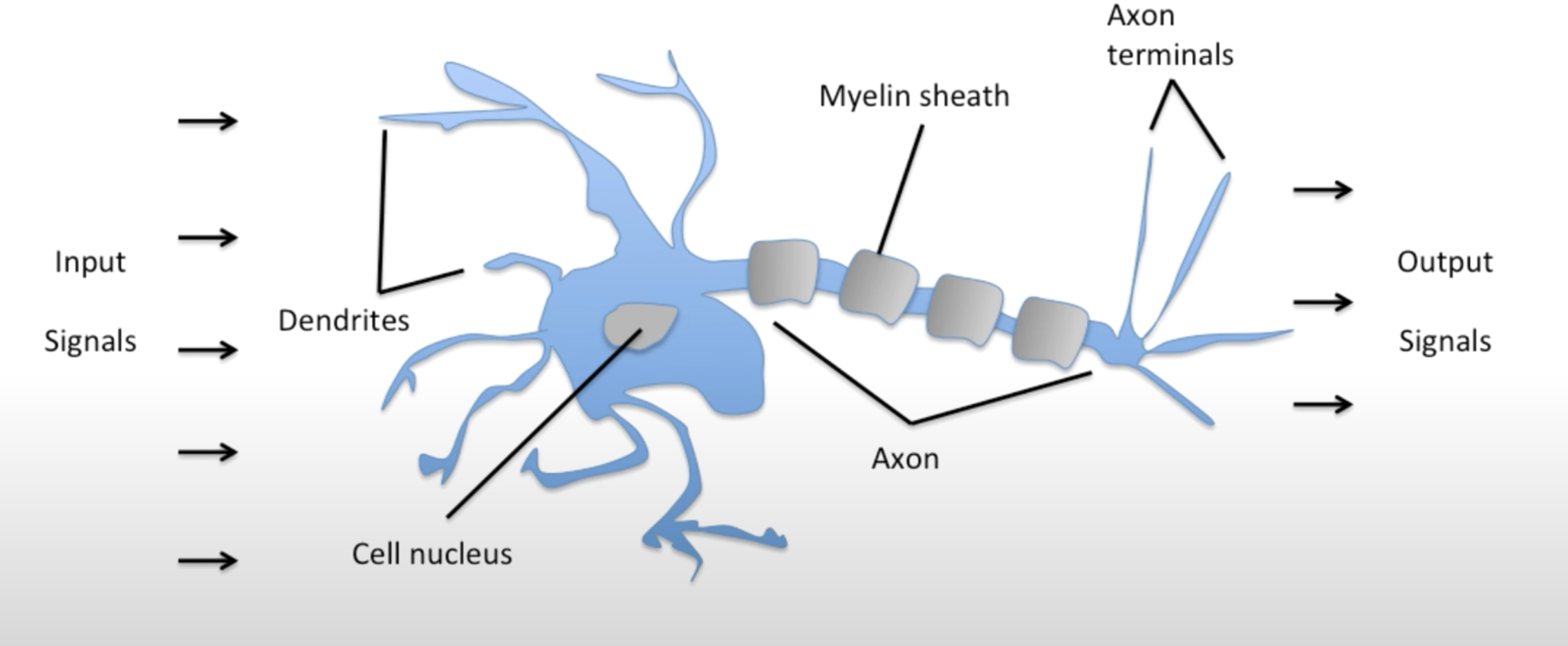
출처: https://sebastianraschka.com 딥러닝은 사람의 뉴런 구조를 모방한 모델이라고 알려져 있습니다. 인간 신체의 뉴런이 입력 신호들을 받아 처리한 후 출력 신호를 내보낸다는 점에 착안해 Perceptron 구조가 디자인되었습니다. Perceptron을 설명하기 전에 먼저 Linear Regression을 먼저 설명하겠습니다.

Linear Regression Linear Regression은 주어진 변수들에 따른 데이터를 가장 잘 표현하는 선형방정식을 찾아가는 문제입니다.
많은 데이터들이 있을 때에 이를 표현하는 선형방정식을 y = Wx + b (W for Weight, b for bias)로 나타내고 Loss Function이 작아지도록 W와 b를 점점 근사해나가며 풀어갑니다. 여기서 Loss Function은 얼마나 현재의 모델이 데이터들을 잘 표현하는지 나타내는 도구인데 후에 기회가 된다면 Optimizer와 함께 설명하도록 하겠습니다:)

출처: https://ujjwalkarn.me Perceptron은 위와 같은 Linear Regression 문제를 풀기 위해 도식적으로 input 값들을 받으면 그에 따른 weight를 곱하고 내부에서 Activation function을 통해 결과를 산출해냅니다. 그렇지만, 위의 perceptron만으로는 정말 다양한 모양을 가지고 있는 데이터를 충분히 표현하기는 어렵겠죠? 그렇기 때문에 이를 여러 층으로 쌓은 Neural Network이 등장하게 됩니다.
Neural Network

출처: https://cs231n.github.io/convolutional-networks/ 위와 같이 input layer와 output layer 사이에 층을 쌓는 것입니다. 예를 들어 28X28 사이즈의 이미지를 넣어 이것이 0~9 중 어떤 숫자를 의미하는지 나타내려면 input layer는 28X28개의 input을 받아야 할 것이고, 출력 값은 0~9 중 어떤 값에 가장 가까운지를 나타내는 확률 값이 될 것입니다. 그렇기 때문에 input layer와 output layer의 차원 수는 우리가 알 수 있겠지만, hidden layer의 차원 수는 층을 쌓는 사람의 생각에 달려있겠죠? 그렇기 때문에 이를 hidden layer라고 표현하며, 이 hidden layer를 통해 보다 세밀한 모델을 학습할 수 있게 됩니다.
여기서 중요한 내용이 빠져있습니다. 이렇게 모델을 구축하는 것은 알겠는데, 어떻게 학습하는 걸까요?
답은 Backpropagation(역전파)에 있습니다.
Backpropagation

Neural Network에서 hidden layer들을 통해 output layer에 결괏값을 출력했다면, 진짜 정답과 비교해볼 수 있겠죠? 그리고 Loss Function을 통해 실제 답과 우리의 모델이 추론해낸 예측값이 얼마나 차이나는지도 수치로 나타낼 수 있을 것입니다. 그리고 그 loss 값을 output layer에서 다시 hidden layer로 전파하며 기존의 weight 값들을 하나하나 loss 값을 최소화하기 위한 방향으로 수정해나가는 것입니다. 이것이 Neural Network에서 말하는 학습이며, 이런 일련의 과정을 거친 학습의 결과물은 오늘날 몇몇 task에서는 사람보다도 나을 정도의 성능을 보여주고 있습니다. 다만, 이러한 방식의 학습이 정말 많은 연산량을 요하기에 시간이 오래 걸릴 뿐만 아니라 정말 뛰어난 성능을 내는 모델은 기업이 아니면 감당할 수 없을 만큼의 컴퓨팅 파워를 요합니다. 개인적으로 이러한 부분에서도 최적화가 이루어져 좀더 상용화에 다가갔으면 하는 마음입니다.