-
[논문리뷰] SATRN: On Recognizing Text of Arbitrary Shapes with 2D Self-AttentionArtificial Intelligence/Computer Vision 2020. 9. 13. 22:28
최근에 OCR (Optical Character Recognition)을 공부하며 관련 논문들을 읽고 있는데요, Clova AI에서 최근에 관련 논문을 내주셨다고 해서 읽어보게 되었습니다. 감사하게도 코드를 오픈소스로 공개해주시고 자료가 잘 정리되어 있어서 공부에 많은 도움이 되었습니다. 이 글의 내용은 상기 논문의 내용 및 이미지를 참고했음을 밝힙니다.
기존 방식의 문제점
Scene Text Recognition (STR)은 자연 상태의 이미지에서 주어진 텍스트의 내용을 알아내는 기술입니다. 이 과정에서 이미지의 특징을 추출하는 데에 CNN을 사용하고, Seq2Seq 구조의 RNN을 사용하여 순차적인 의존성을 파악하고, 그에 따른 문자열을 생성해내는 것이 기본 골자입니다.
기존의 방법은 입력 텍스트가 수평으로 쓰여 있을 것이라는 가정하에 만들어졌기 때문에 2차원의 이미지 데이터의 height component를 없애고 1차원의 feature map으로 처리하여 사용합니다. 그렇지만 실제 환경에서의 텍스트는 세로로 쓰여 있거나 둥근 모양을 가지는 등 불규칙적인 형태가 많기 때문에 이러한 방식은 분명한 한계를 지닙니다.

불규칙한 텍스트 이미지의 예시 ※ OCR을 해당 논문에서는 STR (Scene Text Recognition) 이라고 표현하고 있습니다.
이전의 해결 시도들
1) 표준화
이런 한계점을 극복하기 위한 시도들이 물론 존재합니다. 대략 2가지로 나뉘는데요, 첫 번째 접근은 불규칙한 텍스트 이미지를 수평으로 정렬된 높이와 넓이가 균일한 문자열로 표준화하는 것이지요. 이 과정에서 STN (Spatial Trnsformation Network)이 사용됩니다.

표준화 이전의 텍스트 이미지 
표준화 이후의 텍스트 이미지 STN을 이용한 표준화에는 크게 3가지 문제점이 있습니다. 첫째로는 무엇보다 변환의 종류가 셀 수 없이 다양한데, 이를 수작업으로 하나하나 지정할 수밖에 없다는 것, 둘째로는 수직으로 쓰인 글자와 같이 표준과 너무 동떨어진 입력 이미지는 표준화하기 어렵다는 것 그리고 마지막으로 표준화 과정에서 이미지의 디테일이 손상된다는 점입니다.
2) 2차원 feature map 사용
문제의 원인이었던 1차원 feature map 대신 height component를 유지하여 2차원 feature map을 추출하는 방법 또한 제시되었습니다. 좋은 해결책이지만, 여전히 Deep CNN을 기반으로 한 feature extractor를 사용하다보니 이미지 내의 문자들 간의 공간적 관계(어떻게 배열되어 있는지)를 포착할 수 없다는 한계점이 있었습니다.
SATRN (Self-Attention Text Recognition Network)
Clova AI는 상기의 한계점을 극복하기 위해 원래는 1D sequential data에서 순서상의 의존도를 파악하기 위해 제시된 모델인 Transformer를 2D feature map에서 공간적 의존도를 파악하기 위해 몇 가지의 수정을 거쳤습니다. 이를 통해 얻게 된 SATRN 모델에서 다음과 같은 3가지 성과를 거두었다고 말하고 있습니다.
① Self-Attention 메커니즘을 기반으로 한 네트워크를 제시함으로써 "불규칙한" 데이터셋들에 대해 SOTA 성능을 성취
② Transformer의 encoder가 2D input에 적합하도록 개선하였으며, 속도와 메모리 사용량에 있어서의 우수성을 입증할 분석 자료 제공
③ Self-Attention이 일반 STR 과제뿐 아니라 multi-line / heavily rotated text에 대해서도 잘 작동한다는 것에 대한 실증적 분석 제공

SATRN 구조 Encoder
SATRN 구조에서 가장 핵심이 되는 encoder 부분입니다. 간단하게 말하자면 SATRN은 Transformer를 STR task에 맞게 변형시킨 모델인데요, 그런 만큼 데이터를 받아들이는 부분인 encoder의 구조에 대해 상세히 설명하고 있습니다. 때문에, 이번 포스팅에서는 encoder에 대해서만 다루고, 전체적인 구조가 궁금하신 분은 Transformer에 대해서 좀더 학습하시길 권장합니다.
- Shallow CNN Block
SATRN은 우선 input image를 프로세싱하기 위해 Shallow CNN Block을 사용합니다. 특히나 연산량 부담이 많은 Self-Attention에서 input image의 모든 정보를 그대로 전달하는 것은 연산 비용에 있어서 커다란 부담이 될 수 있기 때문에 기본적인 패턴 및 구성 정보를 추출해내고 추상화하는 과정을 통해 그런 부담을 줄여준다고 합니다. 여기서 shallow는 neural network가 한 개의 hidden layer를 가지고 있다는 것을 의미하지만 'block'이라고 명시되어있는 만큼, 3X3 커널의 Convolutional Layer와 2X2 커널의 Max pooling Layer로 구성된 CNN이 2개 있는 구조로 구성되어있습니다.
- A2DPE(Adaptive 2D Positional Encoding)
RNN structure와 같이 순차적으로 token을 받지 않아 입력값들의 순서를 알 수 없다는 점을 보완하기 위해 positional vector를 도입한 Transformer와 같이 SATRN 또한 무작위적으로 배열된 character들의 위치 정보를 파악하기 위해서 2D로 확장된 positional vector를 도입합니다.
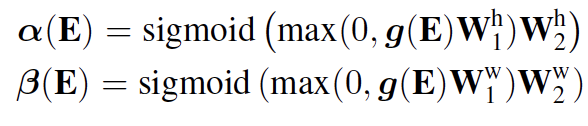
scale factor 먼저 다양한 input feature map에 대해 일정한 기준으로 표준화를 해주어야 할 필요성이 있기 때문에 scale factor α(E)와 β(E)를 통해 각각 세로축과 가로축의 상대적인 비율을 조정하여 height와 width의 positional encoding에 반영합니다. 여기서 g(E)는 E에서의 모든 feature를 average pooling한 값을 뜻합니다.

A2DPE 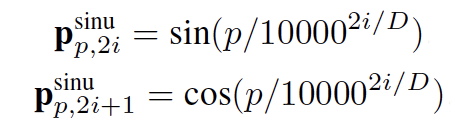
positional encoding 최종 positional vector는 위의 scale factor를 height와 width의 sinusoidal positional encoding에 곱해줌으로써 결정지어집니다. sinusoidal positional encoding은 위와 같이 계산됩니다. 여기서 p는 position에서의, i는 hidden dimension에서의 인덱스값입니다. D는 총 hidden dimension 값입니다.

이와 같이 계산된 A2DPE는 위와 같이 더해져 (h, w)에 있는 entry 값이 key vector, (h', w')에 있는 entry 값이 query vector로 작용했을 때의 attention weight을 계산하는 데에 쓰입니다.
- Locality-aware feedforward layer
위의 여러 층의 Self-Attention을 이용한 A2DPE가 긴 범위에서의 공간적 의존도를 파악하는 데에 쓰였다면, locality-aware feedforward layer는 국소적인 공간 의존도를 파악하는데에 사용됩니다. 기존의 point-wise feedforward layer에서 Depthwise 3X3 convolution layer를 더함으로써 더 효율성을 높였다고 합니다.
결과

위는 SATRN과 여타 STR 기법들의 Accuracy를 비교한 표입니다. SATRN은 목표했던 불규칙적인 데이터셋에 대해 최고의 성능을 갱신했을 뿐 아니라 일부 규칙적 데이터셋에 대해서도 1위의 성능을 기록하고 있습니다. 물론 아직 개선의 여지가 남아있는 수치이지만 앞으로 많은 STR 모델들에 Transformer가 적용되지 않을까 하는 기대를 품어봄직한 성과입니다. 마지막으로, 여기에서 Clova는 친절하게도 모델의 코드를 공개해두었으니 자세한 구현사항이 궁금하신 분들은 확인해보셔도 좋을 것 같습니다:) 조만간 다른 논문리뷰로 돌아오겠습니다!
'Artificial Intelligence > Computer Vision' 카테고리의 다른 글
[논문리뷰] Generative Adversarial Nets (0) 2021.05.13 [코드리뷰] StarGAN (0) 2021.05.04 [논문리뷰] StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation (2) 2021.03.30 [논문리뷰] CRAFT: Character Region Awareness for Text Detection (0) 2021.03.21 [논문리뷰] FaceForensics++: Learning to Detect Manipulated Facial Images (0) 2021.03.10