[코드리뷰] StarGAN
지난번에는 StarGAN 논문을 훑어보며 StarGAN이 어떻게 여러 도메인 간의 translation을 하나로 통합하여 학습하며 그것이 어떻게 더 좋은 결과를 가져오는지를 살펴보았습니다. 수식 등을 통하여 이론적으로 어느 정도 파악했으니, 코드를 살펴봄으로써 어떻게 각 이론들을 실제로 구현하였는지 알아보는 것이 매우 큰 도움이 되리라 봅니다. 공식 코드 출처는 다음과 같습니다.
https://github.com/yunjey/stargan
yunjey/stargan
StarGAN - Official PyTorch Implementation (CVPR 2018) - yunjey/stargan
github.com
DataLoader
def get_loader(image_dir, attr_path, selected_attrs, crop_size=178, image_size=128,
batch_size=16, dataset='CelebA', mode='train', num_workers=1):
"""Build and return a data loader."""
transform = []
if mode == 'train':
transform.append(T.RandomHorizontalFlip())
transform.append(T.CenterCrop(crop_size))
transform.append(T.Resize(image_size))
transform.append(T.ToTensor())
transform.append(T.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5)))
transform = T.Compose(transform)
if dataset == 'CelebA':
dataset = CelebA(image_dir, attr_path, selected_attrs, transform, mode)
elif dataset == 'RaFD':
dataset = ImageFolder(image_dir, transform)
data_loader = data.DataLoader(dataset=dataset,
batch_size=batch_size,
shuffle=(mode=='train'),
num_workers=num_workers)
return data_loader우선, DataLoader를 리턴하는 함수입니다. 각 이미지마다 CenterCrop(), Resize() 그리고 Normalize()을 취해주며 train mode일 경우 Data Augmentation을 위해 RandomHorizontalFip()을 취해주는 것을 확인할 수 있습니다. 대부분의 이미지 DataLoader에 쓰이는 일반적인 조합입니다. 공개된 코드에서는 CelebA와 RaFD 데이터셋에 대한 학습을 진행하므로 이에 대한 정보를 바탕으로 전처리해주고 잇습니다. RaFD는 특별히 복잡한 구성을 가진 데이터셋이 아니기에 PyTorch 내장 ImageFolder 함수로도 충분하지만, CelebA는 구조가 복잡하기에 별도의 Class를 선언하여 전처리를 진행합니다.
Model
Residual Block
class ResidualBlock(nn.Module):
"""Residual Block with instance normalization."""
def __init__(self, dim_in, dim_out):
super(ResidualBlock, self).__init__()
self.main = nn.Sequential(
nn.Conv2d(dim_in, dim_out, kernel_size=3, stride=1, padding=1, bias=False),
nn.InstanceNorm2d(dim_out, affine=True, track_running_stats=True),
nn.ReLU(inplace=True),
nn.Conv2d(dim_out, dim_out, kernel_size=3, stride=1, padding=1, bias=False),
nn.InstanceNorm2d(dim_out, affine=True, track_running_stats=True))
def forward(self, x):
return x + self.main(x)ResidualBlock을 선언하는 class입니다. 당연하게도 forward에서 input과 output을 더해주는 것을 확인할 수 있고, Block 내부는 Conv2d + InstanceNorm2d 2개 사이에 ReLU가 Activation Function으로 끼어 있는 모습입니다. 개인적으로 익숙하게 봤던 Batch Normalization이 아닌 Instance Normalization을 사용하고 있어서 찾아봤는데, 둘의 공식은 같지만 Batch Normalization은 전체 Dataset 기준으로 Batch를 Normalize하는 것이라면, Instance Normalization은 Batch 단위로 Instance들을 Normalize한다는 차이점이 있다고 합니다. 아래 링크에 설명이 잘 되어있습니다.
stackoverflow.com/questions/45463778/instance-normalisation-vs-batch-normalisation
Instance Normalisation vs Batch normalisation
I understand that Batch Normalisation helps in faster training by turning the activation towards unit Gaussian distribution and thus tackling vanishing gradients problem. Batch norm acts is applied
stackoverflow.com
Generator
class Generator(nn.Module):
"""Generator network."""
def __init__(self, conv_dim=64, c_dim=5, repeat_num=6):
super(Generator, self).__init__()
layers = []
layers.append(nn.Conv2d(3+c_dim, conv_dim, kernel_size=7, stride=1, padding=3, bias=False))
layers.append(nn.InstanceNorm2d(conv_dim, affine=True, track_running_stats=True))
layers.append(nn.ReLU(inplace=True))
# Down-sampling layers.
curr_dim = conv_dim
for i in range(2):
layers.append(nn.Conv2d(curr_dim, curr_dim*2, kernel_size=4, stride=2, padding=1, bias=False))
layers.append(nn.InstanceNorm2d(curr_dim*2, affine=True, track_running_stats=True))
layers.append(nn.ReLU(inplace=True))
curr_dim = curr_dim * 2
# Bottleneck layers.
for i in range(repeat_num):
layers.append(ResidualBlock(dim_in=curr_dim, dim_out=curr_dim))
# Up-sampling layers.
for i in range(2):
layers.append(nn.ConvTranspose2d(curr_dim, curr_dim//2, kernel_size=4, stride=2, padding=1, bias=False))
layers.append(nn.InstanceNorm2d(curr_dim//2, affine=True, track_running_stats=True))
layers.append(nn.ReLU(inplace=True))
curr_dim = curr_dim // 2
layers.append(nn.Conv2d(curr_dim, 3, kernel_size=7, stride=1, padding=3, bias=False))
layers.append(nn.Tanh())
self.main = nn.Sequential(*layers)
def forward(self, x, c):
# Replicate spatially and concatenate domain information.
# Note that this type of label conditioning does not work at all if we use reflection padding in Conv2d.
# This is because instance normalization ignores the shifting (or bias) effect.
c = c.view(c.size(0), c.size(1), 1, 1)
c = c.repeat(1, 1, x.size(2), x.size(3))
x = torch.cat([x, c], dim=1)
return self.main(x)Generator입니다. 대칭적인 조건으로 Downsampling과 Upsampling이 이루어지는 중간에 ResidualBlock을 Bottleneck Layer로 사용하고 있습니다. 물론 Generator인 만큼 입력값과 같은 사이즈의 출력값을 내놓도록 설계되었습니다. 또한, forward()에서 condition이 이미지 사이즈에 맞춰 확대되고 concatenate되는 방식으로 학습이 이루어지는 것을 볼 수 있습니다.
Discriminator
class Discriminator(nn.Module):
"""Discriminator network with PatchGAN."""
def __init__(self, image_size=128, conv_dim=64, c_dim=5, repeat_num=6):
super(Discriminator, self).__init__()
layers = []
layers.append(nn.Conv2d(3, conv_dim, kernel_size=4, stride=2, padding=1))
layers.append(nn.LeakyReLU(0.01))
curr_dim = conv_dim
for i in range(1, repeat_num):
layers.append(nn.Conv2d(curr_dim, curr_dim*2, kernel_size=4, stride=2, padding=1))
layers.append(nn.LeakyReLU(0.01))
curr_dim = curr_dim * 2
kernel_size = int(image_size / np.power(2, repeat_num))
self.main = nn.Sequential(*layers)
self.conv1 = nn.Conv2d(curr_dim, 1, kernel_size=3, stride=1, padding=1, bias=False)
self.conv2 = nn.Conv2d(curr_dim, c_dim, kernel_size=kernel_size, bias=False)
def forward(self, x):
h = self.main(x)
out_src = self.conv1(h)
out_cls = self.conv2(h)
return out_src, out_cls.view(out_cls.size(0), out_cls.size(1))
Discriminator입니다. 논문에서도 밝혔듯 PatchGAN에서 따왔음을 밝히고 있으며, 위의 Generator, ResidualBlock과 달리 ReLU가 아닌 LeakyReLU를 사용하고 있습니다. 또한, 이미지가 아닌 클래스 자체에 대한 분포도 학습하므로 conv1은 이미지를 학습하고, con2는 클래스를 학습하도록 설계되어있습니다. 그리고 forward() 에서 두 output의 차원을 맞춰서 리턴해주는 것을 확인할 수 있습니다.
Train
공개된 코드는 train 함수가 2개 있는데 RaFD와 CelebA 둘 중 하나만 학습하는 train() 함수와 둘 다 학습하는 train_multi 함수입니다. 아무래도 train_multi가 StarGAN의 의의를 더 잘 나타낸다고 생각하기에 train_multi 코드를 중점적으로 보겠습니다.
Process Input Data
# Fetch real images and labels.
data_iter = celeba_iter if dataset == 'CelebA' else rafd_iter
try:
x_real, label_org = next(data_iter)
except:
if dataset == 'CelebA':
celeba_iter = iter(self.celeba_loader)
x_real, label_org = next(celeba_iter)
elif dataset == 'RaFD':
rafd_iter = iter(self.rafd_loader)
x_real, label_org = next(rafd_iter)
# Generate target domain labels randomly.
rand_idx = torch.randperm(label_org.size(0))
label_trg = label_org[rand_idx]
if dataset == 'CelebA':
c_org = label_org.clone()
c_trg = label_trg.clone()
zero = torch.zeros(x_real.size(0), self.c2_dim)
mask = self.label2onehot(torch.zeros(x_real.size(0)), 2)
c_org = torch.cat([c_org, zero, mask], dim=1)
c_trg = torch.cat([c_trg, zero, mask], dim=1)
elif dataset == 'RaFD':
c_org = self.label2onehot(label_org, self.c2_dim)
c_trg = self.label2onehot(label_trg, self.c2_dim)
zero = torch.zeros(x_real.size(0), self.c_dim)
mask = self.label2onehot(torch.ones(x_real.size(0)), 2)
c_org = torch.cat([zero, c_org, mask], dim=1)
c_trg = torch.cat([zero, c_trg, mask], dim=1) 역시 DataLoader로 가져온 데이터를 전처리하는 것으로 시작합니다. 랜덤 순열을 통해 Generator가 생성해낼 target condition을 만들어냅니다. 그리고 CelebA와 RaFD를 함께 학습시키기 위한 Mask Vector의 구현이 여기서 등장하는데, 0만 있는 tensor인 zero와 1만 있는 tensor인 mask를 condition 변수와 concatenate하는데, CelebA의 경우에는 condition-zero-mask 순으로 붙이고, RaFD의 경우에는 zero-condition-mask 순으로 붙이는 방식으로 구현한 것을 확인할 수 있습니다.
Train the discriminator
# Compute loss with real images.
out_src, out_cls = self.D(x_real)
out_cls = out_cls[:, :self.c_dim] if dataset == 'CelebA' else out_cls[:, self.c_dim:]
d_loss_real = - torch.mean(out_src)
d_loss_cls = self.classification_loss(out_cls, label_org, dataset)
# Compute loss with fake images.
x_fake = self.G(x_real, c_trg)
out_src, _ = self.D(x_fake.detach())
d_loss_fake = torch.mean(out_src)
# Compute loss for gradient penalty.
alpha = torch.rand(x_real.size(0), 1, 1, 1).to(self.device)
x_hat = (alpha * x_real.data + (1 - alpha) * x_fake.data).requires_grad_(True)
out_src, _ = self.D(x_hat)
d_loss_gp = self.gradient_penalty(out_src, x_hat)
# Backward and optimize.
d_loss = d_loss_real + d_loss_fake + self.lambda_cls * d_loss_cls + self.lambda_gp * d_loss_gp
self.reset_grad()
d_loss.backward()
self.d_optimizer.step()
# Logging.
loss = {}
loss['D/loss_real'] = d_loss_real.item()
loss['D/loss_fake'] = d_loss_fake.item()
loss['D/loss_cls'] = d_loss_cls.item()
loss['D/loss_gp'] = d_loss_gp.item()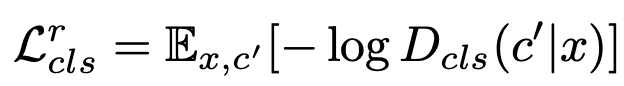
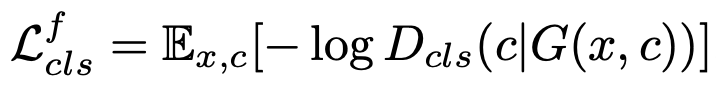

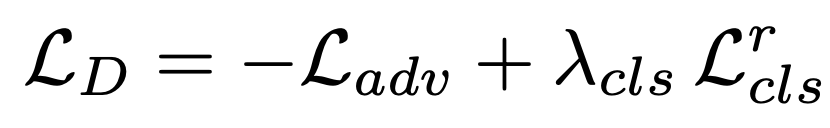
위의 식을 보고 d_loss의 우변을 확인한다면 d_loss_real + d_loss_fake + self.lambda_gp * d_loss_gp 부분이 Adversarial Loss를 나타내고, self.lambda_cls * d_loss_cls 가 Discriminator Loss의 나머지 부분인 것을 확인할 수 있다. 참고로 lambda와 gradient penalty 부분은 config를 통해 hyperparameter로 주어진다.
Train the Generator
if (i+1) % self.n_critic == 0:
# Original-to-target domain.
x_fake = self.G(x_real, c_trg)
out_src, out_cls = self.D(x_fake)
out_cls = out_cls[:, :self.c_dim] if dataset == 'CelebA' else out_cls[:, self.c_dim:]
g_loss_fake = - torch.mean(out_src)
g_loss_cls = self.classification_loss(out_cls, label_trg, dataset)
# Target-to-original domain.
x_reconst = self.G(x_fake, c_org)
g_loss_rec = torch.mean(torch.abs(x_real - x_reconst))
# Backward and optimize.
g_loss = g_loss_fake + self.lambda_rec * g_loss_rec + self.lambda_cls * g_loss_cls
self.reset_grad()
g_loss.backward()
self.g_optimizer.step()
# Logging.
loss['G/loss_fake'] = g_loss_fake.item()
loss['G/loss_rec'] = g_loss_rec.item()
loss['G/loss_cls'] = g_loss_cls.item()
loss['D/loss_real'] = d_loss_real.item()
loss['D/loss_fake'] = d_loss_fake.item()
loss['D/loss_cls'] = d_loss_cls.item()
loss['D/loss_gp'] = d_loss_gp.item()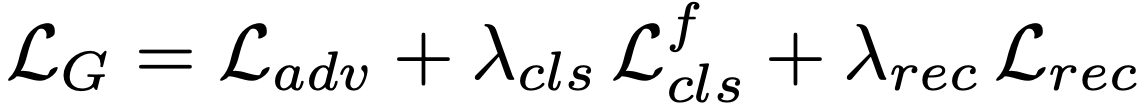
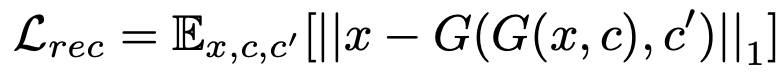
Reconstruction Loss는 논문에 쓰여진 것과 같이 계산되지만 Generator Loss는 Adversarial Loss가 g_loss_fake밖에 없는 것을 확인할 수 있습니다. Adversarial Loss에서 Generator와 관련된 부분만 학습하도록 하는 것으로 보입니다.
Test
def test_multi(self):
"""Translate images using StarGAN trained on multiple datasets."""
# Load the trained generator.
self.restore_model(self.test_iters)
with torch.no_grad():
for i, (x_real, c_org) in enumerate(self.celeba_loader):
# Prepare input images and target domain labels.
x_real = x_real.to(self.device)
c_celeba_list = self.create_labels(c_org, self.c_dim, 'CelebA', self.selected_attrs)
c_rafd_list = self.create_labels(c_org, self.c2_dim, 'RaFD')
zero_celeba = torch.zeros(x_real.size(0), self.c_dim).to(self.device) # Zero vector for CelebA.
zero_rafd = torch.zeros(x_real.size(0), self.c2_dim).to(self.device) # Zero vector for RaFD.
mask_celeba = self.label2onehot(torch.zeros(x_real.size(0)), 2).to(self.device) # Mask vector: [1, 0].
mask_rafd = self.label2onehot(torch.ones(x_real.size(0)), 2).to(self.device) # Mask vector: [0, 1].
# Translate images.
x_fake_list = [x_real]
for c_celeba in c_celeba_list:
c_trg = torch.cat([c_celeba, zero_rafd, mask_celeba], dim=1)
x_fake_list.append(self.G(x_real, c_trg))
for c_rafd in c_rafd_list:
c_trg = torch.cat([zero_celeba, c_rafd, mask_rafd], dim=1)
x_fake_list.append(self.G(x_real, c_trg))
# Save the translated images.
x_concat = torch.cat(x_fake_list, dim=3)
result_path = os.path.join(self.result_dir, '{}-images.jpg'.format(i+1))
save_image(self.denorm(x_concat.data.cpu()), result_path, nrow=1, padding=0)
print('Saved real and fake images into {}...'.format(result_path))Test Code입니다. Train 때와 마찬가지로 CelebA와 RaFD에 대해 다른 순서로 zero와 mask를 붙이는 방식으로 condition 변수를 만들어 Generator에 넣어주고 이미지를 저장합니다. 아무래도 GAN 모델이다 보니 별도의 metric이 있다기보다는 이미지를 저장하고 사람이 정확도를 확인하는 식으로 점검하는 것 같습니다.