[논문리뷰] StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation

개요
기존의 GAN 기반 Image-to-Image Translation 모델들은 domain을 바꿀 때마다 해당 translation에 대한 모델을 가지고 있어야 했습니다. 예를 들어 blond hair와 black hair라는 두 domain에 대해 학습할 때, blond에서 black으로 바꾸는 모델과 black에서 blond로 바꾸는 모델이 별개로 존재한단 이야기입니다. 때문에 k개의 도메인을 가지고 있을 때에 k(k - 1)개의 translation model을 가지게 되며, 이는 데이터를 충분히 활용하지 못하는 동시에 parameter 수를 불필요하게 늘리는 결과를 낳았습니다.
StarGAN은 이러한 점에 착안해 서로 다른 domain 간의 translation을 단 하나의 모델로도 가능하도록 설계하였으며, mask vector를 활용해 다른 domain에 대한 label을 가지고 있는 데이터셋에 대해서도 함께 학습할 수 있도록 하여 parameter의 수를 매우 줄이는 동시에 적은 데이터를 가진 domain에 대해서도 보다 효율적인 학습이 가능케 하였습니다.
Training
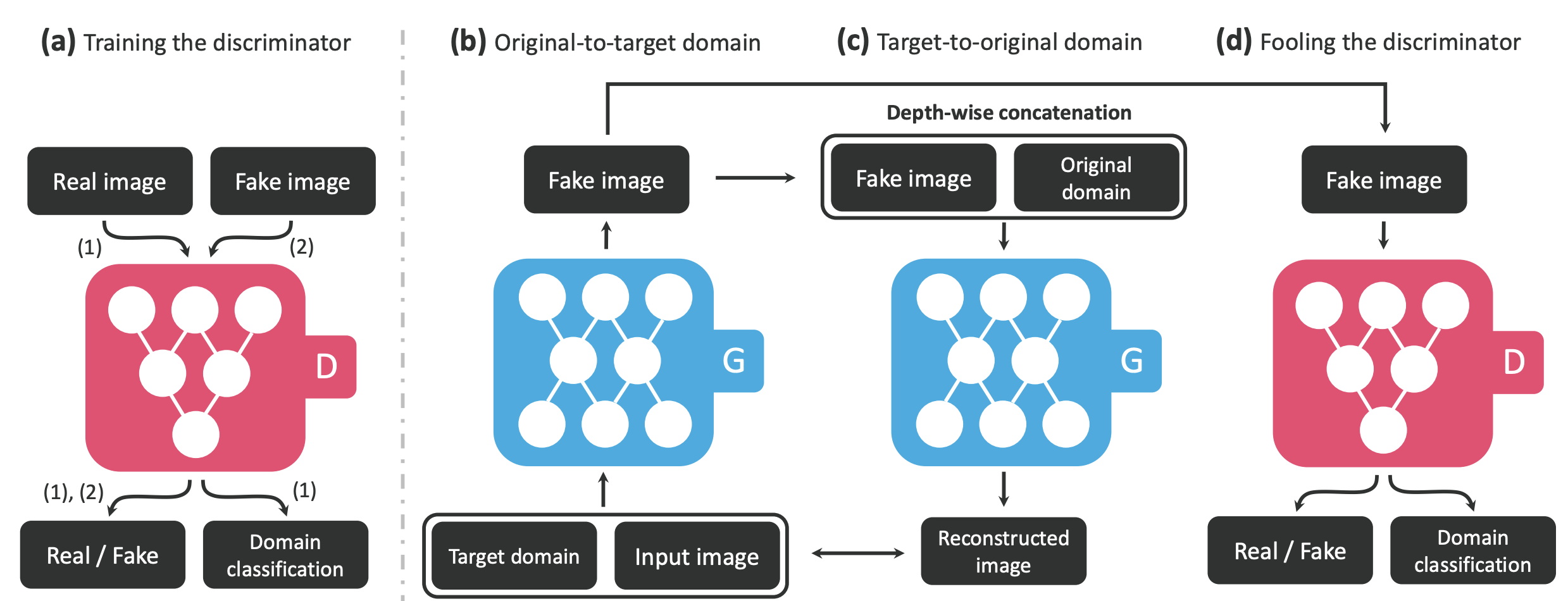
output image $y$를 조건 $c$에 맞춰 생성하기 위해 generator $G$는 $G(x, c)$ → $y$에 따라 학습되며 discriminator $D$는 이미지에 대한 확률분포 $D_{src}(x)$뿐 아니라 domain label에 대한 확률분포 $D_{cls}(x)$ 역시 학습한다.
Loss
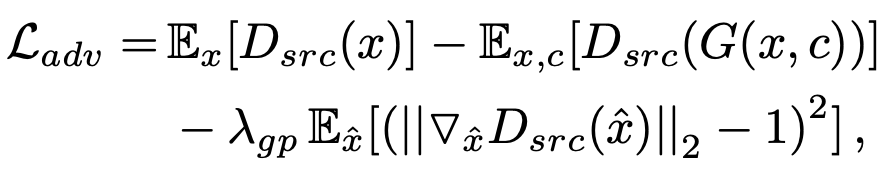
Adversarial Loss는 WGAN-gp의 것을 차용했다. Discriminator는 fake image에 대해 0으로 수렴할 수 있도록 -로, Generator는 Discriminator에 대해 1로 수렴할 수 있도록 +로 더해지게 된다.
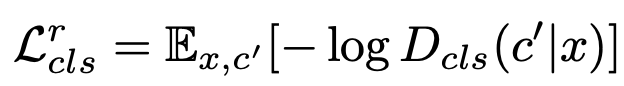
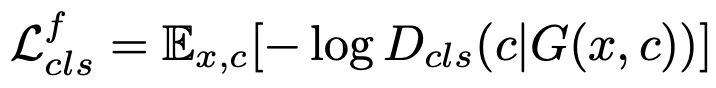
Domain Classification Loss는 Discriminator는 real image의 input data에 대해 해당 domain을 판별할 수 있도록 학습하고, Generator는 generated image에 대해 입력된 class가 포함시키도록 학습하도록 구성되어있다.
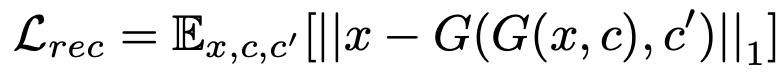
Reconstruction Loss는 모델이 class가 포함된 사진을 외워 출력하는 것을 방지하고자 translated image에서 original image를 복원하며 학습한다.

위의 Loss들을 이용하여 최종적으로 도출한 Discriminator와 Generator의 Full Objective는 위와 같다.
Mask Vector

서로 다른 데이터셋은 다른 attribute들에 대한 label들을 가지고 있다. 예를 들어 CelebA 데이터셋은 머리 색깔과 성별에 대한 label을 담고 있고, RaFD 데이터셋은 'happy'나 'angry' 등 표정에 대한 label을 가지고 있다. 이런 경우에는 translated image로 input image를 학습하는 과정에서 label이 부족하기 때문에 문제가 발생할 수 있다. 때문에, 최종 domain label은 mask vector $m$을 포함하여 나타내게 된다. 예를 들어, $c_{1}$만 학습하는 경우, $m$은 $[1, 0, 0, ...]$의 모습일 것이다. 이렇게 함으로써 모델은 0에 해당하는 dataset의 label들을 무시하도록 학습하고, 다른 데이터셋에 대해 같은 Discriminator 모델을 학습시킬 수 있다.
Experiments
실험은 DIAT, CycleGAN, IcGAN 모델에 비교하여 진행되었다. conditional vector가 존재하는 IcGAN과 달리 한 번에 하나의 attribute translation만 지원하는 두 모델에 대해서는 multi-step translation을 진행하였다.
CelebA

CelebA에 대해 시행한 translation result를 확인해보았을 때, 타 모델에 비해 StarGAN의 visual quality가 더 좋은 것을 확인할 수 있다. 이를 논문에서는 translation마다 별도의 모델을 두는 것이 아닌 하나의 모델로 다양한 translation을 학습함으로써 보다 universal하게 적용될 수 있게 한 것의 결과라고 보고 있다. 추가적으로, IcGAN은 저차원의 latent vector로 이미지의 정보를 나타내어 정보 손실이 일어나는 것으로 보이지만, StarGAN은 CNN에서의 activation map을 바탕으로 spatial information을 보관하기에 차이가 두드러진다.

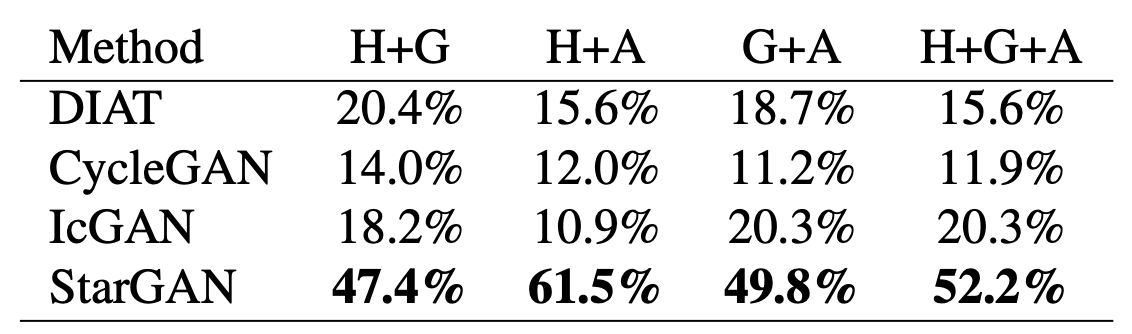
Amazon Mechanical Turk (AMT)에서 어떤 모델의 image translation이 가장 뛰어난지 직관적으로 뽑는 설문조사를 진행했고, single attribute transfer와 multi-attribute transfer에 대해 각각 진행한 결과 둘 모두에서 압도적인 결과를 보였으며, 특히 multi-attribute transfer에 관해서는 다른 모델들과 모든 domain에 대해 큰 차이를 보였다.
RaFD

위에서 확인해볼 때, 다른 모델들에 비해 StarGAN이 확연히 보다 자연스러운 이미지를 생성해내고 있는 것을 확인할 수 있다. IcGAN은 상기 언급한 문제로 인해 personal identity를 보존하지 못하는 모습을 보인다. 그리고 저자들은 이것이 역시 multi-task learning setting으로 인한 성과라고 주장한다. RaFD는 특히나 domain당 500개의 이미지로 그 수가 매우 적어 학습이 어려운데 DIAT이나 CycleGAN은 한 번에 2개의 domain들간의 transfer만 학습할 수 있어 1000개씩 사용하는 반면에 StarGAN은 4000개 이미지 모두를 충분히 활용할 수 있다. multiple domain translation이 가능하기 때문이다.

ResNet을 통해 이미지에 대한 Class classification을 학습시키고 이에 따른 error를 모델별로 살펴보았을 때, StarGAN이 가장 낮았다. 또한, translation에 하나의 모델만을 사용함으로써, 가장 적은 수의 parameter를 가지고 있다.
CelebA + RaFD

RaFD만으로 학습한 StarGAN-SNG와 RaFD, CelebA를 모두 학습한 StarGAN-JNT를 비교해보았을 때, 후자가 배경 및 얼굴 표현에 있어서 더욱 나은 모습을 보여주는 것을 확인할 수 있다. 데이터셋을 모두 활용함으로써 low-level task인 facial keypoint detection and segmentation을 보다 낫게 훈련하고 있음을 알 수 있다.

mask vector가 의도한 대로 잘 학습되었는지 보기 위해서 mask vector를 반대로 주고 똑바로 준 것과 비교해보았다. 그 결과 바꾸고자 한 attribute이 제대로 translate된 윗줄과 달리 RaFD의 facial expressions label들이 무시되고 반대로 CelebA의 facial attributes label이 활성화되어 그 중 한 feature인 young이 0으로 나타나 그 반대인 old로 변화시킨 것을 확인할 수 있다. 결과적으로, mask vector가 의도대로 학습이 잘 되었다는 것이다.
Conclusion
결과적으로 multiple domain 간의 translation을 한 쌍의 generator와 discriminator를 통해 수행해냄으로써 scalability는 물론이고, 더 보편적인 학습을 한 덕에 나은 visual quality를 생산하는 모델을 만들었을 뿐 아니라 다양한 데이터셋을 한꺼번에 활용할 수 있게함으로써 image translation에 많은 기여를 한 논문이다.